About six weeks ago, we introduced you to Deserved Run Average (DRA),1 our new metric for evaluating past pitcher performance at Baseball Prospectus. We gave you both the overview of why a new pitcher performance metric was needed and explained in detail how the metric worked and the equations we were using to get there. We even subjected one of the authors to intense questioning.
After considering the comments we received and a few additional thoughts of our own, we've made some minor revisions. Many readers also asked us for a "DRA minus" statistic that would allow them compare different pitcher seasons across different years and eras. We've done that too.
Finally, other readers asked that we break down some examples of DRA value calculations so that even if you can't (or don't want to) do the modeling yourself, you at least understand why DRA acts in the way it does, and why it does a better job than ERA and FIP in evaluating pitcher quality. We'll take these topics in order.
A Refresher
Before we begin, let's provide a brief reminder of what DRA is and how it works.
DRA is premised on the notion that while a pitcher is probably the player most responsible, on average, for what happens while he is on the mound, he is not responsible for everything. DRA therefore only assigns the runs a pitcher most likely deserved to be charged with.
DRA works through a multi-step process.
The first (and most important) thing DRA does is to look at the average value each pitcher provides during each plate appearance, something we call value/pa. This does multiple things differently from ERA in order to do a better job. These include: (1) discarding the distinction between earned and unearned runs; (2) using individual batters faced rather than outs; (3) using base-out run expectancy rather than raw runs; and (4) most importantly, adjusting each batting event for the effect of the opposing batter, receiving catcher, and umpire behind the plate on each play. Then, value/pa controls for various externalities that can add noise to the signal of a pitcher's performance. These include:
-
Catcher framing (CSAA)
-
Game-time temperature
-
The pitcher's team defense (FRAA)
-
The inning and base-out state of the at-bat
-
The score
-
The handedness of the batter (but not the pitcher)2
-
Whether the pitcher is at home or away
-
The stadium in which the game is occurring.
This first step of DRA, calculating value/pa, is a linear mixed model that predicts the most likely effect of each pitcher on the likelihood of run-scoring during an average plate appearance. We subtract the total value of an average pitcher facing the same circumstances from the total value offered by the subject pitcher, divide it by the number of batters faced, and end up with each pitcher's value/pa.
We then run a second, non-linear model that regresses value/pa along with other metrics we've created against the overall run expectancy rate (RE24/EV) for all baseball events for which each pitcher was on the mound.3 (We'll use "EV" as shorthand for "events" going forward.) These other metrics include the pitcher's rate of bases stolen (Swipe Rate Above Average, or SRAA), the pitcher's rate of base-stealing attempts (Takeoff Rate Above Average, or TRAA), the pitcher's rate of passed balls and wild pitches (Errant Pitches Above Average, or ERAA), the proportion of batters the pitcher faced as a starter versus in a relief role (Starting Pitcher Percentage, or SPP), and finally the number of batters the pitcher has seen (log_bf).
It's important to note that this second model actually chooses for us which predictors are most important for a given season, based on its analysis of the previous three seasons.4 Value/pa and log_bf (the natural log of batters faced) are always selected, whereas other variables appear only in some seasons. A chart with each season's chosen variables is in the Appendix, but notable trends include that (1) SRAA was fairly important in run-scoring from the early 1960s through the early 1990s, (2) EPAA was fairly important in the mid-1990s, and (3) SPP is otherwise a popular third choice. The reasons these variables are selected probably relates to different run environments, and more analysis is warranted as to why certain variables are selected in certain eras.
This second model gives us a predicted RE24/EV for each pitcher, which is then converted to outs and put on the same scale as runs-allowed per nine innings (RA/9) by multiplying each pitcher's personal ratio of outs to baseball events. We add the constant necessary to put the pitchers on the same scale as each season's average RA/9, and voila: There is your DRA.
The updated specifications for these models are provided in the Appendix.
Revisions to DRA and its Components
At the end of the introductory article, we published a list of the top 25 DRAs over the previous 25 seasons (1989 through 2014). This initial version of DRA ranked Pedro Martinez in 2000 as the best (lowest) DRA of the past 25 years. That was hardly controversial, but Pedro's 1999 did not even make the list of top-25 seasons, even though Pedro allowed fewer runs in 1999 than 2000 and his peripherals from the two seasons are similar. Several readers asked about this and it is a very fair question.
The performance of DRA, as applied to the overall player population, is excellent. As we explained in the Introduction, DRA explained about 70 percent of pitcher runs allowed in each full season, even including pitchers with as few as one batter faced. This far exceeds the performance of any other publicly available estimator, and indicates that the method, overall, is sound.
However, that doesn't mean there wasn't room for improvement. As we reviewed the code for our primary DRA component, pitcher value per plate appearance (value/pa), we noticed coding choices that could affect outliers, the sorts of pitchers who would end up on a top-25 list. For example, we were including both our three-year park factors as well as each stadium's in-year park factor in value/pa. We originally included both to account for possible in-season differences, but park factor was also creating unnecessary overlap. So we took it out. We also changed temperature to a log transformation to put that predictor on a closer scale to the others.
After making these changes, we found that while the overall performance of DRA in the population was essentially unchanged, our outliers (i.e. our most interesting cases) looked better. The formula for our tweaked value/pa is in the Appendix.
Here is the revised chart of the top 25 DRAs in baseball, for qualified starters, over the past 25 years:
|
Name |
Season |
DRA |
RA/9 |
|
2011 |
1.92 |
2.62 |
|
|
Pedro Martinez |
2000 |
1.93 |
1.82 |
|
Justin Verlander |
2012 |
2.04 |
3.06 |
|
2014 |
2.16 |
1.91 |
|
|
1995 |
2.18 |
1.67 |
|
|
2013 |
2.27 |
3.07 |
|
|
2004 |
2.30 |
3.36 |
|
|
Pedro Martinez |
1997 |
2.30 |
2.42 |
|
2014 |
2.32 |
2.72 |
|
|
Clayton Kershaw |
2013 |
2.40 |
2.10 |
|
2013 |
2.40 |
2.45 |
|
|
2014 |
2.40 |
2.54 |
|
|
2012 |
2.41 |
3.12 |
|
|
Clayton Kershaw |
2011 |
2.41 |
2.55 |
|
2013 |
2.42 |
2.32 |
|
|
1992 |
2.42 |
2.66 |
|
|
2014 |
2.42 |
2.48 |
|
|
1995 |
2.43 |
2.73 |
|
|
1993 |
2.46 |
2.79 |
|
|
Pedro Martinez |
1999 |
2.49 |
2.36 |
|
Randy Johnson |
2004 |
2.49 |
3.22 |
|
2011 |
2.56 |
2.50 |
|
|
Pedro Martinez |
2005 |
2.58 |
2.86 |
|
2011 |
2.59 |
3.03 |
|
|
1989 |
2.59 |
2.54 |
We suspect you'll like this leaderboard better. Remember, of course that these pitchers are pitching in different seasons and their numbers cannot be directly compared to each other: That is what DRA– is for. (We'll talk about that shortly).
Nonetheless, these are the qualified starters whose combination of skill and their run environment produced the lowest seasonal DRAs since 1989. There is a collection of the greats (Martinez, Johnson, Kershaw) and a few outstanding individual seasons as well. Justin Verlander's 2011 season nudges out Pedro's 2000 for the lowest qualified starter DRA in this group, but that is due to the dampened run environment of 2011.
Jason Schmidt's 2004 remains one of the best pitching seasons by a starter in recent memory, at least in DRA's opinion. We'll discuss why that it is in a moment.
Reader Guy noted that DRA values for the best pitchers in the original article consistently skewed lower than their RA/9 values. We don't see that necessarily being a problem, given that survival bias by definition favors better players and because DRA also by definition accounts for factors that RA/9 by itself does not. Regardless, in checking all qualified pitchers from 1989 to the present time, we find that the average (revised) DRA is 4.24 while the average RA/9 is 4.25. Thus, to the extent any such skew was a problem in the original version, we consider it to be addressed.
DRA-Minus ("DRA–")
As noted above, we've received multiple requests for a "minus" version of DRA, something that rates pitchers by how well they compared to their peers rather than by an amount of predicted runs allowed in a given season. Knowledgeable baseball fans are familiar with statistics like this. Common examples include wRC+ and ERA-. The idea is to put an average player for each season at 100, and then rate players by how much they vary from the average. By rating every pitcher by how good (or poor) he was by comparison to his peers, we can make fairer comparisons across different seasons and different eras. These comparisons aren't perfect: We can't make baseball 50 years ago more diverse or force today's players to endure the conditions of 50 years ago, but metrics like DRA– allow comparisons of pitchers across seasons and eras to be much more meaningful.
Unlike cFIP (which measures true talent), DRA– (which measures true talent plus luck) will not have a forced standard deviation. The two numbers (which are otherwise both scaled to 100) can still be compared, but be mindful of that distinction. For both cFIP and DRA–, lower is better.
For your enjoyment, we'll once again give you a leaderboard. These are the best (lowest) seasons of DRA–. Many of these entries will be unsurprising, while others may remind you of a pitcher you had forgotten, and still others may spark vigorous discussion.
Here are the top 50 DRA– scores for starters with 162-plus innings pitched since 1953. They are based on our revised DRA values:
|
Name |
Season |
DRA |
DRA– |
|
Pedro Martinez |
2000 |
1.93 |
37 |
|
Greg Maddux |
1995 |
2.18 |
45 |
|
Justin Verlander |
2011 |
1.92 |
45 |
|
1988 |
1.86 |
45 |
|
|
Justin Verlander |
2012 |
2.04 |
47 |
|
Jason Schmidt |
2004 |
2.30 |
47 |
|
Pedro Martinez |
1997 |
2.30 |
48 |
|
Pedro Martinez |
1999 |
2.49 |
48 |
|
Randy Johnson |
1995 |
2.43 |
50 |
|
1963 |
2.01 |
51 |
|
|
1974 |
2.10 |
51 |
|
|
1968 |
1.74 |
51 |
|
|
1968 |
1.74 |
51 |
|
|
Randy Johnson |
2004 |
2.49 |
51 |
|
1999 |
2.69 |
52 |
|
|
Kevin Appier |
1993 |
2.46 |
53 |
|
Clayton Kershaw |
2014 |
2.16 |
53 |
|
Max Scherzer |
2013 |
2.27 |
54 |
|
1988 |
2.26 |
54 |
|
|
Sandy Koufax |
1965 |
2.18 |
55 |
|
1965 |
2.18 |
55 |
|
|
Gio Gonzalez |
2012 |
2.41 |
55 |
|
Pedro Martinez |
2005 |
2.58 |
55 |
|
Curt Schilling |
2002 |
2.60 |
56 |
|
Clayton Kershaw |
2011 |
2.41 |
56 |
|
Pedro Martinez |
1998 |
2.71 |
56 |
|
Juan Marichal |
1966 |
2.26 |
57 |
|
Roger Clemens |
1997 |
2.73 |
57 |
|
1967 |
2.15 |
57 |
|
|
Garrett Richards |
2014 |
2.32 |
57 |
|
2007 |
2.77 |
57 |
|
|
Greg Maddux |
1994 |
2.84 |
57 |
|
Clayton Kershaw |
2013 |
2.40 |
57 |
|
Jose Fernandez |
2013 |
2.40 |
57 |
|
1972 |
2.13 |
58 |
|
|
1981 |
2.31 |
58 |
|
|
Matt Harvey |
2013 |
2.42 |
58 |
|
Greg Maddux |
1998 |
2.80 |
58 |
|
Greg Maddux |
1997 |
2.79 |
58 |
|
1957 |
2.50 |
58 |
|
|
Pedro Martinez |
2003 |
2.78 |
58 |
|
Kevin Brown |
2000 |
3.04 |
59 |
|
1975 |
2.47 |
59 |
|
|
Curt Schilling |
1992 |
2.42 |
59 |
|
1980 |
2.52 |
59 |
|
|
Roger Clemens |
1998 |
2.83 |
59 |
|
1966 |
2.35 |
59 |
|
|
Juan Marichal |
1969 |
2.40 |
59 |
|
Adam Wainwright |
2014 |
2.40 |
59 |
|
1962 |
2.65 |
59 |
This chart is interesting for a few reasons. First and foremost, it allows us to compare great seasons from 2000 to great seasons in 1965, giving us a picture of who has been the best over time. You will notice that some of our low-DRA seasons from low run-scoring eras have disappeared, while other performances from low run-scoring eras have retained their impressive quality. This is because unlike DRA itself, which is scaled to each season's environment, DRA– scales players within the season to each other.
DRA– says that the best pitcher season by a starter in recent baseball history was Pedro Martinez in 2000. We'd like to think that not too many people would disagree with that. DRA– is available on our leaderboards next to DRA and cFIP.
DRA Demonstrated
We've had lots of requests for demonstrations of how DRA makes a difference. That's a reasonable request. After all, most of you have been using FIP and ERA, and would like to see some actual proof of why you now ought to be using something else.
To make our point, we thought we would choose some examples that show how FIP and ERA sometimes fail to tell the whole story. In fact, sometimes they mislead you entirely.
Jason Schmidt 2004: One of the Best Ever?
Selling a new statistic can be a difficult task. If too many names are recognizable, people don't see the point of your efforts. If too many names are unfamiliar, people assume you've screwed up. The right mix seems to be a bunch of names people recognize (perhaps in an interesting order) and then a few they don't.
But then you have to defend the names people don't expect, because they are low-hanging fruit. That is certainly true of Jason Schmidt, who the last version of our article ranked as having one of the best DRA seasons of the last 25 years. If anything, we're now doubling down on Schmidt: By DRA–, his 2004 season is tied with Justin Verlander's 2012 for the fourth-best season by a qualified starter in the history of modern baseball.
DRA's relentless promotion of Jason Schmidt's 2004 season caught Rob Neyer's attention. Schmidt's initial DRA was much lower originally than it is now, but Neyer's point stands: Schmidt's extraordinary 2004 DRA, as compared to other pitchers of more renown, is worth explaining. And as it turns out, Schmidt's 2004 is a perfect example of why you should be using DRA, not other metrics, as the best measure of how well a pitcher actually performed.
In 2004, Jason Schmidt had an ERA of 3.20. There are signs that he pitched better than that. His FIP was 2.92 and the BBWAA certainly thought he was a top pitcher: They ranked him sixth in the Cy Young voting. But DRA doesn't just think he was the sixth-best pitcher in 2004; it thinks Schmidt was the best pitcher in 2004, and one of the best ever.
Why? What is DRA noticing? The answer lies in catcher framing, something that DRA considers, and no other metric does.
*** Math Alert ***
We'll generally avoid open math in this article, because those interested in the finer points can look at the equations in the Appendix. But we'll provide one specific example, so if nothing else you can be assured we're not just making this all up.
Schmidt's excellent 2004 DRA stems, as most DRAs do, from his extraordinary rating in value per plate appearance (value/pa). Let's work backward to see how that happened. Here is the final tabulation of value/pa for Schmidt 2004:
-
Name
w_pitcher
wo_pitcher
bf
value
value_pa
Jason Schmidt
-31.61
19.14
907
50.76
+5.6%
Schmidt's value/pa is the highest number for all pitchers that year. Value/pa is, like it sounds, just the total value over average (50.76) divided by the batters faced (907), totaling 5.6 percent.
The "value" in value/pa comes from the columns "w_pitcher" and "wo_pitcher." The former is the value the pitcher provided controlling for the applicable factors we listed above; the latter is the model's prediction of how an average pitcher facing the same opposition under the same circumstances would have performed. The pitcher's net value—as indicated in that column—comes from subtracting the "w_pitcher" value from the "wo_pitcher" column. This gives us each pitcher's value over average.
Jason Schmidt had the fourth highest "w_pitcher" value in 2004. Randy Johnson (-46), Johan Santana (-45), and Ben Sheets (-32) were higher. What Schmidt had over those three was a much higher "wo_pitcher" rating; in other words, DRA thinks Schmidt faced much more unfavorable conditions than Johnson, Santana, or Sheets.
In particular, DRA thinks that Schmidt was forced to tolerate horrible catcher framing. In 2004, Schmidt’s innings were caught by Yorvit Torrealba (who was a horrible framer that year) and A.J. Pierzynski, who was also below average, although not as bad as Torrealba. Regardless, their combination made for a horrible aggregate backstop when it came to framing. Here is a breakdown of how that affected Schmidt:
|
Name |
CSAA |
CSAA Coef |
|
Schmidt |
-0.37 |
-0.03 |
|
PAs |
907 |
|
|
Schmidt Runs Lost |
10.1 |
|
|
Average |
-0.011 |
|
|
Avg Runs Lost |
0.3 |
|
|
RUNS LOST |
9.8 |
There was no easy way to orient this chart, so we'll walk you through it. Jason Schmidt's average CSAA per plate appearances in 2004 was -.37.5 DRA's value calculation is a linear mixed model, so we can back out of it like we would any other linear model. The coefficient for CSAA in the value model for 2004 was -.03. This means that for every batter Schmidt was facing in 2004, Torrealba was framing the strike zone so badly that Schmidt was penalized, on average, .0111 runs per batter (-.03 * -.37). If you multiply that by 907 plate appearances, you end up with over 10 runs lost.
*** End Math ***
It turns out that an average framing catcher with Schmidt's schedule would still give up about .3 runs, but that leaves 9.8 runs that Schmidt gave up solely because he had a terrible strike zone to work with. Of course, there were a few runs gained and lost elsewhere: Schmidt benefited from lower temperatures in San Francisco, but also had to face an equal number of right- and left-handed hitters. Schmidt also had a tougher combination of opponents and parks than Johnson, Santana, or Sheets. Nonetheless, terrible catcher framing is the primary difference-maker and the sole one we'll break down for you today.
The burden of having a terrible pitch-framer is something that DRA alone among pitcher run estimators is capable of noticing. Jason Schmidt gave up 3.36 runs per nine innings in 2004, but he only deserved to give up 2.3. Hence his 2.30 DRA. Schmidt's 2004 is absolutely remarkable considering the wreck of a strike zone he had to deal with, and DRA credits him appropriately for it. ERA, FIP, and other run estimators do not.
The story of Jason Schmidt's 2004 season also offers a rebuttal to those who doubt the value of good framing. If a terrible framer can cost a team almost 10 runs (more than a win) even though he only catches every fifth game, how much damage do you think that catcher could do on a near-daily basis? DRA not only demonstrates why Jason Schmidt deserved much better in 2004, but why sophisticated front offices put such a high value on good catching.
For our second example, we'll go back a bit further in time to look at some other aspects in which DRA makes a real difference.
The Story of 1980: Mario Soto versus Steve Carlton
Who the hell is Mario Soto? Admit it: Many of you who are not Reds fans asked yourselves this very question.
Let's look at some of the statistics for Mario Soto during his DRA–leading 1980 season. Let's compare him to Hall of Famer Steve Carlton in that same season:
-
Name
Team
ERA
ERA+
FIP
BB/9
K/9
DRA
DRA–
Steve Carlton
PHI
2.34
304
162
2.42
2.7
8.5
3.03
70
Mario Soto
CIN
3.07
190 1/3
118
2.95
4.0
8.6
2.50
59
Soto made the DRA– leaderboard above. Carlton did not. DRA and DRA– are telling us that Mario Soto was the best qualified starter in 1980 and one of the best starters of the past 50 years.
On its face, it looks like DRA has made a terrible mistake. In 1980, Soto was a swingman. Carlton was, well, Steve Carlton. In fact, by traditional and even basic sabermetric statistics, Carlton looks to have been better than Soto in every way. Carlton has a better ERA, a far superior ERA+, and a better FIP. He walked fewer batters and struck them out at basically the same rate as Soto. If you are using ERA, FIP, and similar traditional statistics, you would conclude that Carlton was a much better pitcher in 1980 than Mario Soto.
And if you thought that, you would be wrong.
Why? What has DRA noticed about Carlton that FIP and ERA and ERA+ completely missed? Let's start by looking at the different divisions Soto and Carlton played in. Courtesy of our friends at Baseball Reference:
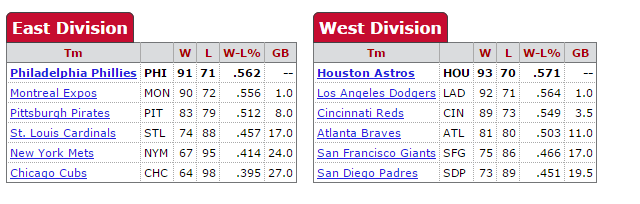
You'll notice that Carlton's Phillies played in a much weaker division than Soto's Reds. The other five teams in the NL East averaged 76 wins, and two of them—the Mets and Cubs—were doormats. By contrast, the other five teams in the NL West averaged 83 wins, and even the worst team, the Padres, managed to win 73 games.
Carlton still managed to pitch a fair number of games against NL West opponents, but by comparison to other pitchers, the overall quality of his opponents was flimsy:
|
Ease of Schedule (Rank) |
oppOBP |
oppSLG |
oppTAv |
oppOPS |
oppRPA+ |
||
|
1 |
Steve Carlton |
PHI |
0.310 |
0.368 |
0.249 |
0.678 |
90 |
|
28 |
Mario Soto |
CIN |
0.317 |
0.376 |
0.256 |
0.693 |
96 |
This information comes from one of our most useful leaderboards: Pitcher Quality of Opponents. This isn't quite the same information that DRA is using, and we haven't backed it out down to the decimal point within value/pa, but this format gives similar information and makes it easier for you to understand what DRA is doing when it corrects for quality of opponents. The Quality of Opponents leaderboard also allows you to look at components (OBP, SLG), composite data (TAv, OPS), and oppRPA+, which scales opponent True Average to 100 so you can see what percent above or below average the quality of a pitcher's opponents was.
What you see is that out of the pitchers who qualified for the ERA title in 1980, Carlton had the easiest lineup of opponents, and it was not close. His opposing lineups got on base the least, slugged the worst, and scored runs at the feeblest rate. Their oppRPA+ of 90—which historically is an incredibly easy schedule—means that they were 10 percent below league average as a group. It was, in other words, a great opportunity for a very good pitcher like Carlton to run up his statistics. Soto faced below-average hitters as well, but his opponents were much closer to average than Carlton's, which means his lesser results end up being more impressive.
But that's not all. The issue isn't only who Carlton faced, but where he got to face them. Here at BP, we have another statistic from the same leaderboard: Pitcher Park Factor, or PPF. It calculates the personal park factor for each pitcher over the course of a season, accounting for each stadium he pitched in during the year; 100 is average, above 100 is hitter-friendly, and below 100 is pitcher-friendly. Carlton isn't getting quite the same benefit from PPF that he got from his opponent quality, but once again, you'll see Soto got a tougher road:
|
Park-Friendliness (Rank) |
NAME |
TEAM |
PPF |
|
48 |
Steve Carlton |
PHI |
101 |
|
71 |
Mario Soto |
CIN |
103 |
(There were 88 qualified pitchers.) Carlton not only got to throw to the weakest lineups; he also got to do it in parks that on balance were friendlier to pitchers. Value/pa notices this too, which means that DRA accounts for it.
We're not done. Value/pa, and thus DRA, takes into account the quality of defense behind the pitcher. Suppose Carlton had pitched to the same number of batters (777) that Soto did. Here is the difference in the average quality of the defenses behind them, as measured by Fielding Runs Above Average (FRAA), our defensive statistic here at BP:
|
Pitcher |
Avg. Defense / PA |
Net Runs |
|
Soto |
–1.99 |
-6.5 |
|
Carlton |
+1.23 |
+4 |
(The coefficient for FRAA was -.04 in 1988.)
Taken together, the balance of equities overwhelmingly favors Soto:
|
Player |
Value w/ Pitcher |
Value w/o Pitcher |
Net Value |
PA |
Value/PA |
|
Soto |
-21.18 |
-0.68 |
20.51 |
777 |
2.6% |
|
Carlton |
-34.5 |
-8.16 |
25.38 |
1228 |
2.1% |
Carlton added more total value than Soto by virtue of his workload, a fact reflected by his higher DRA Wins Above Replacement Player (DRA_PWARP) for the year. That said, the value model predicts that even an average pitcher would have been worth almost 8.2 runs in the highly favorable conditions under which Carlton operated. This narrows the value gap between the two of them considerably, and while Carlton ends up still providing more net value, that is only because he threw more innings. On a rate basis—which is what ERA and FIP are also measuring—Soto was not only a better pitcher, but the most valuable pitcher per plate appearance among qualified starters that year, and one of the 25 most valuable qualified starters of the last 50 years.
Cole Hamels: About that 2014 ERA
We'll conclude with one more example, and this one much more current.
Cole Hamels has pitched well for the Phillies for a long time. He is also one of Ruben Amaro's most coveted assets, a player he has refused to move because the offers so far have allegedly been inadequate.
Hamels is a three-time All-Star and received Cy Young votes in four different seasons. He's also 31 years old, and has a lot of wear on the tires, having pitched over 200 innings five straight years. Amaro, though, is no doubt pitching the notion that Hamels' 2014 season proves he still "has it." Hamels, after all, was sixth in NL Cy Young votes last year, struck out almost a batter per inning, and featured a sparkling 2.46 ERA (2.64 RA/9) for a team with a hitter-friendly park.
Certainly those are shiny numbers for a front office that does not want to look too deep. But did Cole Hamels deserve his 2.46 ERA last year?
FIP is more skeptical of Hamels' 2014 season: It predicts 3.09. That's still really good. DRA is more skeptical still: It rates Hamels' 2014 season as 3.60. That isn't bad, but it's not top-of-the-rotation performance. Among qualified starters for 2014, it fits right in between Jarred Cosart and Chris Tillman.
What concerns DRA about Cole Hamels? Much of it is fairly mild. He gained about four runs from good defense and lost about two runs from subpar framing. He didn't get to pitch at home as much as some, and also had to pitch in slightly higher temperatures. But the big red flag for DRA was the opponents to and ballparks in which Hamels pitched. Here is how his opponents and Pitcher Park Factor (PPF) ranked as compared to other qualified starters in 2014:
|
Name |
oppRPA+ |
PPF |
Opp Rank |
PPF Rank |
Overall |
|
Cole Hamels |
95 |
95 |
5th |
13th |
2nd |
This is another excerpt from that handy Pitcher's Quality of Opponents report that analyzes the strength of a pitcher's opponents and ballparks. Hamels' opponents were 5 percent below average and the stadiums in which he pitched were, taken together, also 5 percent easier than average. That made for the fifth-easiest schedule by opponents, the 13th-easiest by stadium, and, averaging those two values,6 the second-easiest schedule in baseball for a qualified starter in 2014 in those two categories.
While Hamels had an ERA of 2.46 last year, DRA sees that achievement as driven substantially by his schedule. In other words, Hamels pitched like a 3.60 RA/9 pitcher, but a combination of good defense, subpar opponents, and favorable parks are the primary explanation for his sparkling ERA.
Of course, no competent GM would base a trade decision on one season, even the most recent one. Hopefully, rival GMs are focused instead on what Hamels will do for them in the future. And indeed, maybe that is exactly the problem Amaro is facing. Smart GMs likely are seeing a pitcher who would improve any club, but not to the extent that Amaro would like them to believe.
Conclusion
We couldn't answer all of your questions, but we hope we were able to address the most common ones. We believe that DRA remains a major step forward in the estimation of retrospective pitcher quality, and we believe that your analysis will be that much better because of it. Instead of citing ERA or FIP, and then looking for reasons why those statistics might be misleading, you would probably be better off looking first at the pitcher's DRA. With DRA, you receive a much better estimate of each pitcher's fair responsibility for runs allowed on their watch.
Special thanks to Rob McQuown for technical assistance.
Bibliography
Bates D, Maechler M, Bolker B and Walker S (2014). _lme4: Linear mixed-effects models using Eigen and S4_. R package version 1.1-7, http://CRAN.R-project.org/package=lme4.
R Core Team (2015). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. http://www.R-project.org/.
Stephen Milborrow. Derived from mda:mars by Trevor Hastie and Rob Tibshirani. Uses Alan Miller's Fortran utilities with Thomas Lumley's leaps wrapper. (2015). earth: Multivariate Adaptive Regression Splines. R package version 4.4.0. http://CRAN.R-project.org/package=earth.
Appendix
Here are the updated DRA models.
For value/pa:
value.model<- lmer(lwts ~ inning*score_diff + start_bases_cd*outs_ct + csaa + temp_log + bats*stadium + role + fraa*bat_home_id + inning*bat_home_id + (1|batter) + (1|pitcher) + (1|catcher) + (1|umpire), data=value.data.s)
For Swipe Rate Above Average (SRAA):
success.s <- glmer(success ~ inning + stadium + cFIP_log + (1|pitcher) + (1|lead_runner) + (1|catcher), data=success.data, family=binomial(link='probit'), nAGQ=0)
For Takeoff Rate Above Average (TRAA):
attempts.s <- glmer(run_attempt ~ inning * score_diff + stadium + lr_BSAA + c_BSAA + start_bases_cd*outs_ct + cFIP_log + role + (1 | pitcher) + (1 | batter) + (1 | lead_runner) + (1 | catcher), data=attempts.data.s, family=binomial(link='probit'), nAGQ=0)
For RE24/EV, before the conversion to RA/9 scale:
DRA.model.s <- earth (RE24_EV ~ value_pa + BSAA + SBAAA + PBWPAA + SPP + log_bf, data=DRA.data.s, nk=50, weights=DRA.data.s$events, ncross=50, nfold=10, pmethod='cv', linpreds="BSAA", keepxy=TRUE, degree=2, thresh=.005, trace=1)
For DRA–:
DRA.minus.s$DRA_minus <- DRA.data.s$DRA / weighted.mean(DRA.data.s$DRA, DRA.data.s$outs) * 100
Here were the variables the DRA models selected, by season:
|
Model Specification |
Seasons |
|
value_pa, log_bf |
1953-1956, 1960-1961, 1965, 1968-1972, 2013 |
|
value_pa, log_bf, SPP |
1957-1959, 1973, 1978, 1983, 1992-1994, 1997-2001, 2008-2012, 2014 |
|
value_pa, log_bf, SRAA |
1962, 1966-1967 |
|
value_pa, log_bf, SRAA, SPP |
1963-1964, 1976-1977, 1979-1982, 1984-1987, 1990-1991 |
|
value_pa, log_bf, SPP, TRAA |
1974-1975, 1988 |
|
value_pa, log_bf, EPAA, SPP |
1995, 2002-2007 |
|
value_pa, log_bf, EPAA |
1996 |
|
value_pa, log_bf, EPAA, SPP, TRAA |
1989 |
- Michael Humphreys also uses "DRA" to refer to his Defensive Regressed Average, a completely different concept that evaluates historical fielding. An introduction to the concept can be found here. But that DRA should not be confused with Deserved Run Average. ↩
- Can you figure out why that is? ↩
- An event is any plate appearance or action on the bases that results in an advance or an out. ↩
- We use the latest version of the earth package from R, which uses a stepwise forward/backward variable selection procedure. We selected variables with a sensitivity of .005 and used 50 repetitions of 10-fold cross-validation to resist overfitting in variable selection. ↩
- DRA's CSAA number combines the effect of the catcher with that of the umpire and batter on the strike zone, but the latter two are miniscule contributors. ↩
- DRA doesn't just average these two, but again, we're trying to illustrate the principle. ↩
Thank you for reading
This is a free article. If you enjoyed it, consider subscribing to Baseball Prospectus. Subscriptions support ongoing public baseball research and analysis in an increasingly proprietary environment.
Subscribe now
Note, that I'm not saying FRAA or DRA have no value. But I do think some caution around its precision is reasonable. The Jason Schmidt example is a perfect one; much of his over performance is explainable by the effect of CSAA. That is an ideal use of DRA, to identify for us which of the underlying calculations are most responsible for a given result.
Peter Jensen also pointed out that Jason Schmidt was caught by both Torrealba and A.J. Pierzynski in 2004, rather than Torrealba alone as we for some reason originally thought. This doesn't affect the dreadful aggregate strike zone that Schmidt had to deal with that year, but the article now does correctly note that two catchers contributed to it.
Our thanks to Cliff and Peter, and if others have further questions or proposed corrections, please continue to let us know.