We’ve identified incorrect data in the playoff odds report. The purpose of this post is to explain what happened, announce that it’s fixed, and offer some technical notes on the process so readers can reassure themselves that it’s now working as it should.
At the heart of the playoff odds report is a database table that contains the current-season MLB schedule. We use that table for many other products as well. After the season started, we moved many of the other products to a different schedule table that went back through the entire Retrosheet era and also included additional data. The playoff odds were a straggler, because we were working on a project that would allow us to run them for previous seasons. (The adjusted standings have been similarly modified, and soon we’ll have adjusted standings available back through 1974 on the site.) So the changes were made to the new playoff odds codebase, and the old codebase was left running on the old schedule table. Unfortunately, at some point during the season, the old schedule table stopped updating properly.
We’ve subsequently cut the old schedule table entirely, and now all products are running off the new schedule table. The new playoff odds codebase is in place as well, but due to the amount of data that needs to be processed, it will be some time before we’re ready to offer historic playoff odds for past seasons. We have rerun the playoff odds for the entire season, so the one- and seven- day deltas are working off corrected data and thus reflect changes in a team’s odds over time, not the correction of mistakes. Playoff odds for past dates this season can be viewed by clicking on the Hit List and navigating to past editions.
Running the odds over the whole season allows us to verify that the error has been corrected as well. Looking at the predicted win percentage in the report, and compared to the average rest-of-season win percentage from the simulation, we see an average difference of .003. So the simulation is correctly incorporating the inputs, within a certain tolerance. (Because it’s a Monte Carlo simulation, we would expect to see some variation from predicted record due to randomness.)
The next question one might have is how we determine the expected rest-of-season win percentage. There are three inputs:
- A team’s third-order win percentage to date,
- Its projected rest-of-season win percentage in the depth charts, and
- Its strength of schedule (in other words, its opponents’ expected win percentages).
The weighting used varies based upon how many games have been played. Given a team’s third-order and depth chart (DC) winning percentages, we figure its expected win percentage like so:
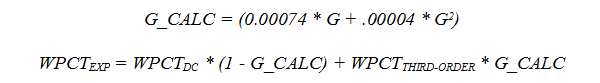
We do this for every team. To figure the odds of the home team winning each game, we add in home field advantage and use the odds ratio, like so:
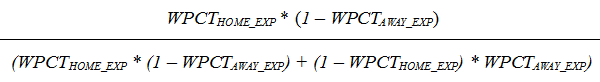
That gives us the home team’s winning percentage for that game. We take the average of this for the listed expected win percentage, so the number you see on the site will not exactly reflect the EXP_WPCT produced by the formula above.
Then, for each iteration of the sim, we produce a random number between zero and one; if the number is below or equal to the winning percentage, the home team wins. Otherwise, it loses. Then we rank the final standings from each simulated season and figure out how many times a team won either its division or one of the two wild cards.
We’ve written several new queries to monitor this report and will be checking on it daily to ensure that problems do not recur.
Thank you for reading
This is a free article. If you enjoyed it, consider subscribing to Baseball Prospectus. Subscriptions support ongoing public baseball research and analysis in an increasingly proprietary environment.
Subscribe now
Are you sure this is correct? I just clicked over to the odds that say they were updated this morning at 7am. And despite the fact that the Red Sox were the only team in the Al East to win yesterday their, 1 day delta is listed as minus 3.5%. That seems....unlikely.
But with the problems solved, and Boston's chances almost having to go up after yesterday, I'd love to hear about this.
I ask this because I look at the Dodgers, who are now 74% to make the playoffs. In the past 7 days, they went 5-2 while the Giants went 4-3, as did the D-Backs. They put their MVP on the DL, and lost their starting 2b and 3b to the DL. And their odds went up 18.5%.
Curiouser and curiouser.