A few weeks ago, during the division series, Brandon McCarthy remarked on Twitter that it would be more interesting for TBS to show a diagram of the batter hot and cold zones for every batter than to show the PitchTrax strike zone and pitch location graphic. He argued that knowledge of the hot and cold zones would give viewers additional insight into the battle between the pitcher and the batter.
The pitcher-batter confrontation lies at the heart of baseball; learning about it is one of my favorite pursuits. Thus, I was intrigued by McCarthy’s comments. As far as I know, no one has published a study about the reliability of batter hot and cold zone data. If batter performance in particular areas of the strike zone is very repeatable, that knowledge could be highly valuable, both to teams and to fans. On the other hand, perhaps such data is no more useful than knowing that a batter is 2-for-10 in the postseason or 3-for-7 against a given pitcher in his career, in which case it might be interesting for entertainment purposes but practically useless for decision-making in a game.
Batter hot and cold zone information has been provided for at least a decade by scouting services like Inside Edge, and teams routinely make this information available to their players. Starting in the 2010 season, MLB Advanced Media’s online Gameday application added hot and cold zone information developed from PITCHf/x data.
{kind=link}
These hot and cold zone reports typically divide the strike zone into nine zones using a 3×3 grid and report the player’s past batting average in each zone over some time period, along with coloration to assist in recognition of the hot and cold areas for the batter. Other analysts and data sources have used other grid sizes to divide the zone, but the 3×3 grid is by far the most popular and recognizable presentation of this data.
Other analysts have recently used heat maps, often based upon PITCHf/x data, for similar purposes without being constrained to a 3×3 grid depiction of the data. TruMedia’s heat maps are a common example.
In addition, hot/cold zones may be based upon slugging average, runs above average, or some other metric besides batting average.
In order to evaluate the usefulness of the hot and cold zone data, I took the results of every plate appearance for which we have detailed pitch location data from PITCHf/x during the period 2007-2011 and assigned those results to the location of the final pitch of each plate appearance. I grouped the pitches by zones for each batter and calculated the average run values for each zone using linear weights. I split the data for each batter into two halves, randomly assigning games from 2007-2011 into each half for comparison.
First, I examined the traditional division of the strike zone into nine zones. I divided all the pitches within the strike zone that ended a plate appearance into nine fixed bins. I separated the pitches vertically at 1.74, 2.30, 2.86, and 3.42 feet. (I ignored the height of the batter, but when I controlled for it later, it had little effect on the split-half correlations.) I separated the pitches horizontally by dividing the plate in thirds at +/-0.83 and +/-0.28 feet.
I ran a regression for all the right-handed batters with at least 630 plate appearances in 2007-2011 that ended on a pitch in the strike zone. I used performance in a given zone in one half of the sample along with performance in the other eight zones in the same half of the sample to predict performance in that zone in the other half of the sample. The resulting regression equation is as follows, where performance is measured in runs above average:
Zone Performance in Split Half 2 = (0.17 * Zone Performance in Split Half 1) + (0.43 * Performance in Other Eight Zones in Split Half 1) + (0.40 * League Average Performance).
The correlation coefficient was r=0.30, and the p-values for both input variables were highly significant (<.0001).
The biggest problem with this data is that, even when considering five seasons, most batters had less than 100 plate appearances of data in both halves of the sample in all of the nine zones. Our best predictive results occur when we use only 17% of the observed zone performance and base the remainder of the prediction on the batter’s overall performance and the league average performance.
There is some true signal there amidst the noise, but if we expect pitchers to form their pitching strategies based upon this data, that signal is very weak. Let’s look at a couple of typical examples.
.jpg)
The first group of zone data suggests that you want to pitch Michael Young on the outer third of the plate or over the middle of the plate if you keep the ball down. If you need to come inside, you might be able to sneak one up and in without too much damage.
If you executed that strategy against Young in the other half of the sample, you would do pretty well in all the zones on the outside third, but you would get killed whenever you tried to sneak one up and in, and you would not do too well with pitches down over the middle of the plate, either.
.jpg)
Yuniesky Betancourt is a weaker hitter, and the zone data from the first half of our sample suggests that the only places in the zone where he is a real threat are up and in and down over the middle of the plate. Moreover, he is very vulnerable both down and away and over the heart of the plate.
A pitcher who pitched to those cold zones in the other half of the sample would find Betancourt a decent hitter and might miss his weakest spots up and away or down over the middle of the plate.
Young and Betancourt are typical examples. At the extremes, Freddy Sanchez is an example of the best zone correlation between sample halves, and Mike Napoli is an example of the worst zone correlation between sample halves.
{kind=link}
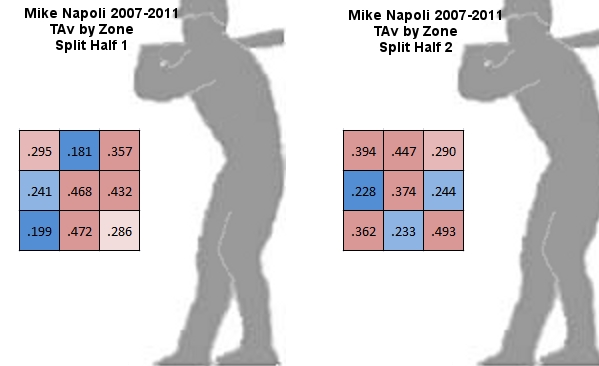{kind=link}
The division of the strike zone into nine boxes does not seem to serve us very well. The hitters do have tendencies toward hot and cold areas, but dividing into nine pieces makes the data very noisy and unreliable, and it becomes difficult to pick the true tendencies out of the vagaries of the noise. Moreover, imagine what would happen to the sample sizes if we split the data further by pitch type or if we used only a single season of data.
Perhaps using fewer zones in order to increase the sample size would produce more statistically meaningful and practically useful results. I experimented with a few different possibilities but ultimately settled on using four zones, including the area outside the strike zone. I extended the sample beyond the boundaries of the strike zone to include the susceptibility of a batter to chasing bad pitches, with the added benefit of increasing the total sample of PA-ending pitches by over 50 percent.
I divided all the pitches that ended a plate appearance into four bins, separated at the vertical and horizontal midpoints of the pitch location distributions. I separated the pitches vertically at 2.4 feet. For right-handed batters, I separated the pitches horizontally at 0.07 feet, just slightly outside from the middle of home plate. For left-handed batters, I separated the pitches horizontally at -0.28 feet, a few inches outside from the middle of home plate.
With larger sample sizes, the split-half correlation improved somewhat, as expected. However, even with only four zones, much noise remained in the results. Here is the regression equation for right-handed batters:
Zone Performance in Split Half 2 = (0.32 * Zone Performance in Split Half 1) + (0.32 * Performance in Other Three Zones in Split Half 1) + (0.36 * League Average Performance).
The correlation coefficient was r=0.46, and the p-values for both input variables were highly significant (<.0001).
With sample sizes from larger zones between 200 and 300 plate appearances in each half of the sample, both the split-half correlations and the statistical significance of the results have improved.
Do the results have better baseball meaning? Let’s revisit a couple of our earlier examples.
.jpg)
We see that Young has a consistent hot zone up and in and that his weakest zone is down and away.

Betancourt is weak on the outside part of the plate and a little closer to capable on the inside half, particularly up and in.
The 3×3 grid contained about the same information as the 2×2 grid, but the 3×3 grid gave us a false sense of greater granularity than is present in the data, at least at the sample sizes we typically have available. Given the limits of the ability of most pitchers to locate within a small zone, the 2×2 grid is likely more representative of actual pitching strategy anyhow.
Heat maps of batter hot and cold zones should be regarded with a similar sense of skepticism, depending on the sample size involved. Such heat maps are drawn from the same underlying data and should have similar statistical correlation between sample halves. If a heat map has insufficient spatial smoothing of the data, it could be an even less reliable predictor of future performance than a 3×3 grid.
Levels of coloration, whether for the gridded bins or for heat maps, are another important facet of how accurately hot and cold zone information is communicated to the viewer. I chose to use six levels of coloration in the examples in this article, with the traditional red for hot and blue for cold. I observed, however, that the switch from light blue (for slightly below average) to light red (for slightly above average) seemed to have more visual impact than the change in performance warranted. I did not experiment further to find an optimal color palette, but I would warn both creators and viewers of hot/cold zone graphs that proper interpretation is heavily affected by the choice of palettes.
Let’s close by looking at the True Average batting leaderboards for the four quadrants of the hitting area for batters with at least 1000 plate appearances in 2007-2011.
|
Hand |
Up-and-In PA |
Up-and-In TAv |
|
|
645 |
.392 |
||
|
686 |
.380 |
||
|
573 |
.377 |
||
|
697 |
.376 |
||
|
723 |
.367 |
||
|
415 |
.365 |
||
|
698 |
.364 |
||
|
659 |
.362 |
||
|
690 |
.362 |
||
|
564 |
.361 |
||
|
Average |
551 |
.279 |
|
|
Average |
447 |
.278 |
|
|
341 |
.221 |
||
|
349 |
.218 |
||
|
571 |
.216 |
||
|
286 |
.216 |
||
|
266 |
.213 |
||
|
327 |
.213 |
||
|
422 |
.213 |
||
|
292 |
.212 |
||
|
355 |
.211 |
||
|
259 |
.205 |
Nelson Cruz, who gained attention for hitting six home runs against the Detroit Tigers in the AL Championship Series, just missed the top ten here, with a .356 TAv in plate appearances that ended on a pitch up and in. All six of his ALCS home runs were hit off pitches up and in.
|
Hand |
Up-and-Away PA |
Up-and-Away TAv |
|
|
419 |
.453 |
||
|
793 |
.383 |
||
|
453 |
.381 |
||
|
671 |
.374 |
||
|
414 |
.373 |
||
|
Albert Pujols |
772 |
.371 |
|
|
411 |
.361 |
||
|
471 |
.359 |
||
|
631 |
.359 |
||
|
530 |
.355 |
||
|
Average |
459 |
.263 |
|
|
Average |
439 |
.288 |
|
|
517 |
.214 |
||
|
Garrett Atkins |
398 |
.212 |
|
|
240 |
.210 |
||
|
329 |
.209 |
||
|
526 |
.207 |
||
|
Jason Kendall |
417 |
.206 |
|
|
480 |
.205 |
||
|
291 |
.202 |
||
|
246 |
.201 |
||
|
279 |
.159 |
|
Hand |
Down-and-In PA |
Down-and-In TAv |
|
|
224 |
.426 |
||
|
Joey Votto |
689 |
.395 |
|
|
549 |
.372 |
||
|
590 |
.372 |
||
|
Mark Teixeira |
472 |
.370 |
|
|
511 |
.365 |
||
|
Miguel Cabrera |
722 |
.363 |
|
|
509 |
.362 |
||
|
Manny Ramirez |
343 |
.361 |
|
|
Josh Hamilton |
482 |
.359 |
|
|
Average |
415 |
.276 |
|
|
Average |
436 |
.278 |
|
|
244 |
.228 |
||
|
Garrett Atkins |
257 |
.226 |
|
|
440 |
.225 |
||
|
254 |
.221 |
||
|
Chris Getz |
307 |
.221 |
|
|
413 |
.216 |
||
|
243 |
.211 |
||
|
249 |
.210 |
||
|
276 |
.208 |
||
|
229 |
.193 |
|
Hand |
Down-and-Away PA |
Down-and-Away TAv |
|
|
714 |
.308 |
||
|
382 |
.293 |
||
|
538 |
.291 |
||
|
623 |
.290 |
||
|
569 |
.285 |
||
|
523 |
.285 |
||
|
Mark Teixeira |
254 |
.284 |
|
|
248 |
.280 |
||
|
423 |
.279 |
||
|
Miguel Cabrera |
693 |
.278 |
|
|
Average |
539 |
.211 |
|
|
Average |
436 |
.219 |
|
|
475 |
.169 |
||
|
515 |
.169 |
||
|
Sean Rodriguez |
264 |
.168 |
|
|
438 |
.164 |
||
|
Jeff Mathis |
384 |
.161 |
|
|
313 |
.161 |
||
|
472 |
.158 |
||
|
Aaron Miles |
278 |
.157 |
|
|
Andy LaRoche |
339 |
.153 |
|
|
588 |
.133 |
Hot and cold zone information for batters does have some predictive value for future performance, but all such data continually flirts with the problem of small sample sizes, more so as the hitting area is divided into smaller grids or more granular heat maps. Aggregating into bigger zones improves the predictability. A 2×2 grid works fairly well with multi-year samples, but for smaller samples of data, even that level of aggregation may not be sufficient to render the hot and cold zone information useful.
Thank you for reading
This is a free article. If you enjoyed it, consider subscribing to Baseball Prospectus. Subscriptions support ongoing public baseball research and analysis in an increasingly proprietary environment.
Subscribe now
I definitely agree that as a next step, you could evaluate hot/cold zones based upon performance on all pitches, and of course you would need to baseline the performance on each pitch to the ball-strike count.
I think the key to understanding the link between the 4 or 9 'zones' and a heatmap is this: a heatmap essentially does the same thing. The main difference is that the 'zones' are continuous throughout the entire strike zone, which requires the heat map to use a weighted average of adjacent data. This is essentially lots of tiny blocks like above, but with a weighted averaging between blocks.
But things can really, really break down when there is not adjacent data (edge of where the batter swings). This is why I have stuck to using heat maps exclusively for density of pitches thrown or for umpire calls. Sample sizes are sufficient and there are generally not artificial boundaries to the smooth. Even then, using a heat map for umpire calls should be 1) Cross-validated and 2) Use a lot lot lot of data. Without CV, comparison between umpires with different sample sizes will be difficult upon visual inspection (the entire point of a heatmap). Without lots of data, CV breaks down with certain types of analyses (especially in the binomial and ordinal realm), and in that case you have no idea if you are smoothing optimally.
In the end, pitch data is just extremely noisy. Location and pitch type matters less than knowing where the pitch will end up (a hypothesis by me). As a professional hitter, if you're a crappy outside pitch hitter, but you know it's coming, you can probably hit a fastball out of the park. We don't know "when" the batter guesses right on a pitch and even then, it's difficult to hit any pitch, which creates this large amount of noise.
Lastly: thank you for pointing out the color palette issue! While I often use a Blue-to-Yellow-to-Red palette (most natural interpretation), I have noticed that using a single color presents the best representation when attempting to interpret the smooth at a more granular level visually. In this latter case, there isn't a "breakpoint" of interpretation of the color scheme.
I'm partially color blind, so I may be a bad interpreter of this sort of thing.
What is the average hitter performance in each of the 9 zones?
I haven't calculated the average performance for lefties in the 9 zones, but here are the average TAv numbers for RHB:
Up+in = .248
Up+middle = .279
Up+away = .244
Middle+in = .289
Middle+middle = .315
Middle+away = .245
Down+in = .295
Down+middle = .279
Down+away = .205
In practice, pitchers/catchers/coaches integrate this data-driven approach with qualitative assesments of hitters (using video, scouting reports, etc.), and the combined analysis is much more meaningful than just looking at data-driven hot and cold zones. If I know a hitter stands close to the plate but does not have quick hands, the only way he is hitting a good inside fastball is by cheating, which opens him up to an offspeed pitch outside. I don't need much data at all to predict his vulnerabilities and develop a strategy - he can hit one or the other but not both, so I just need to know which is which. The amount of data I need to determine that would be statistically insignificant in a study such as this one. So in other words, I think the integration of qualitative information alleviates or at least significantly reduces SSS problems for those who are actually making these decisions. This is also why, with advance scouting, pitchers' approaches to hitters can change numerous times throughout a season as both pitcher and batter make adjustments, even though partial season data wouldn't be statistically significant.
One other note, I view hot/cold zones as nearly meaningless without any pitch-type overlay. It's pretty rare that a strategy would entail throwing any pitch you want as long as it's high and outside, for example. That makes the sample size smaller still, but as noted above this can be overcome by integrating qualitative information.
I am not advocating the idea that the pitcher should just go up there and throw whatever pitch he wants wherever he wants and ignore scouting the hitters. That probably works for some pitchers, but I don't knock the value in scouting the opposition for those who find it helpful.
There are certainly more sophisticated approaches to this problem, both qualitatively and quantitatively. Quantitatively, I ultimately believe the right approach is to build a swing model and test it against the empirical results (and the qualitative observations) rather than simply reporting the empirical results in zones and ignoring the question of why/how it happens.
I have heard it said that lefties are particularly adept at hitting pitches down and in. This study seems to show that they really aren't any better at this aspect than righties.
Very good stuff, Mike!
If we wanted specifically to investigate how lefties and righties did in various parts of the zone, it might make sense to break that out by pitch type. Once we throw the whole league into the sample together, our sample sizes get much, much bigger, and we can safely break it down into additional categories without worrying about sample size being too small.
Dave Allen had a good series of posts on that topic:
Run Value by Pitch Location
Run Value by Pitch Type and Location
Home Run Rate by Pitch Location
Deconstructing the Fastball Run Value Map
Deconstructing the Non-Fastball Run Maps
1) checking for reliability of your data before diving into validity
2) looking specifically at what your results mean in terms of effect sizes, etc.
3) using good examples to illustrate the emenaingfulness and limitations of your data.
The world would be a better place if more "experts" and reporters did the same in other areas of research/policy.
What about splitting up the data into 5 zones instead of 4? Have one for the middle (to separate out the heart of the plate) and 4 L shapes for the corners. I imagine most hitters will be very good at hitting pitches in the heart of the plate so separating that information out from the corners might be useful.